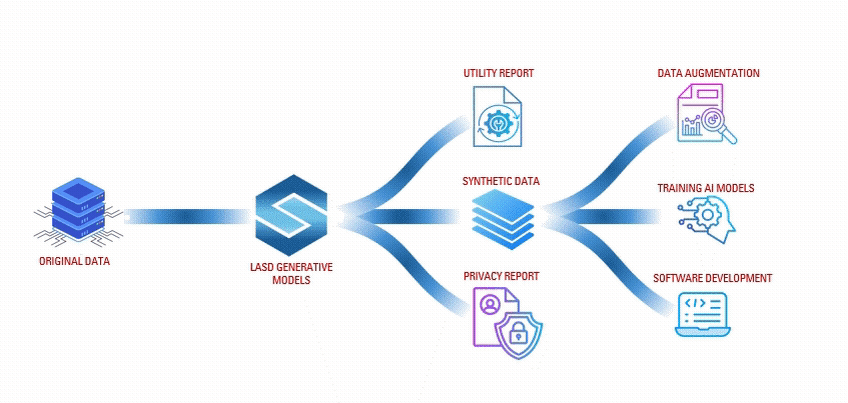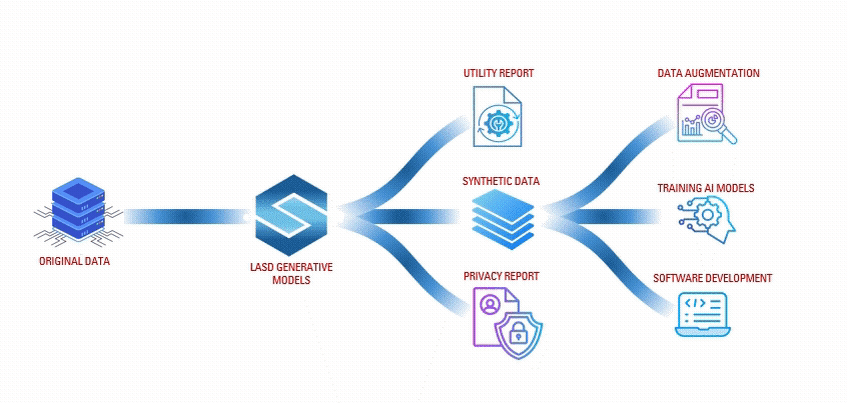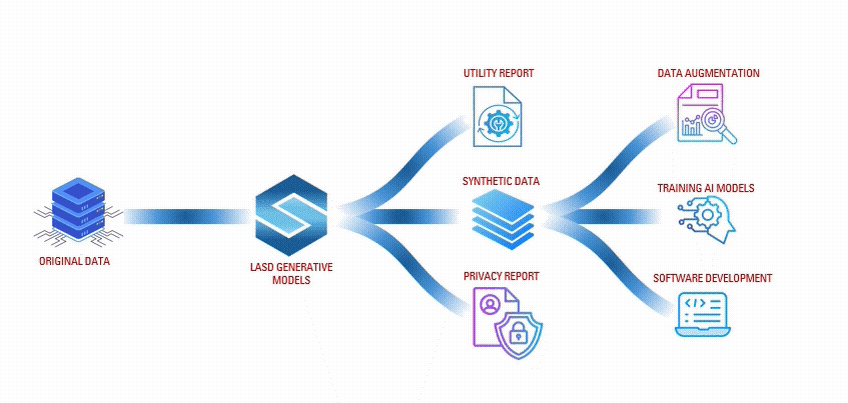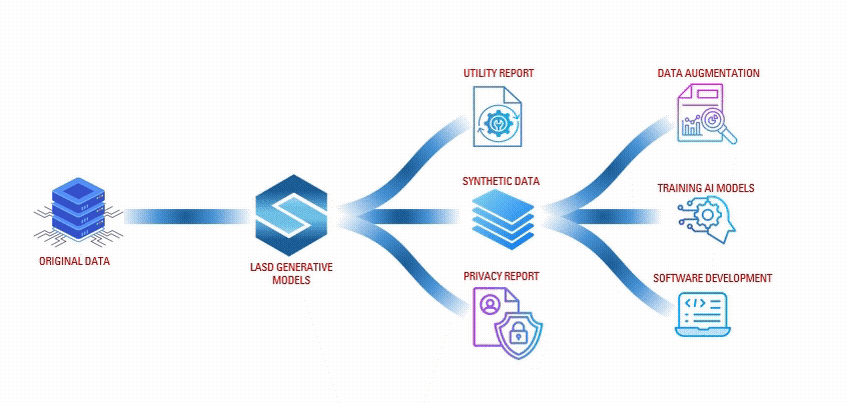
Data Privacy Protection
Synthetic data ensures personal information remains secure by mimicking real data without exposing sensitive details, helping organisations comply with regulations like GDPR while maintaining data utility.

Data Augmentation
By generating additional examples, synthetic data helps improve the performance of machine learning models, especially when real data is limited or unbalanced, boosting accuracy in educational applications.

Cost-Effective Data Generation
Creating synthetic data is faster and more affordable than collecting real-world data, allowing for large-scale data generation without the high costs of manual data collection and labeling.

Bias Reduction
Synthetic data allows for controlled data generation, reducing bias and ensuring fair outcomes in AI systems, especially important in education where fairness and inclusivity are key.

Training AI Models
With synthetic data, AI models can be trained in diverse educational scenarios where real data is scarce, allowing for faster prototyping and more robust solutions.

Safe Experimentation Environment
Synthetic data provides a risk-free space for testing algorithms and systems, enabling innovation without the consequences of using sensitive real-world data.